안녕하세요 모닝수잔입니다 :)
실제 업무에서 가장 유용하게 사용될 수 있는 RPA로 PDF에서 데이터를 추출하는 방법에 대해 알아보겠습니다.

PDF파일은 크게 Native-text format과 Scanned image 2종류로 나눌 수 있습니다. PDF 파일에서 마우스 드래그로 데이터를 긁었을 때 각각의 텍스트가 블록으로 지정된다면 Native-text format으로 손쉽게 데이터 추출이 가능하고, 그 반대로 문서 전체가 블록으로 지정된다면 Scanned image로 OCR을 활용해야 데이터 추출이 가능해집니다. 즉, 정의를 살펴보니 아시겠지만 Scanned image의 경우 텍스트가 아니라 이미지로 인식되고 OCR을 통해 텍스트를 읽어내기 때문에 그 결과값이 100% 정확하지는 않답니다.
※ OCR(Optical Character Reader)
광학적 문자 판독 장치란, 빛을 이용해 문자를 판독하는 장치로 종이에 인쇄되거나 손으로 쓴 문자, 기호, 마크 등을 빛에 비추어 그 반사 광선을 전기 신호로 바꾸어 컴퓨터에 입력하는 장치이다. (by. 네이버 시사상식사전)
예제를 통해 바로 시작해보겠습니다.
우선은 Uipath의 Activities Panel에서 "PDF"라는 키워드로 검색해보시면 검색결과가 없으실텐데요, PDF 액티비티 패키지를 추가로 설치해줘야합니다.
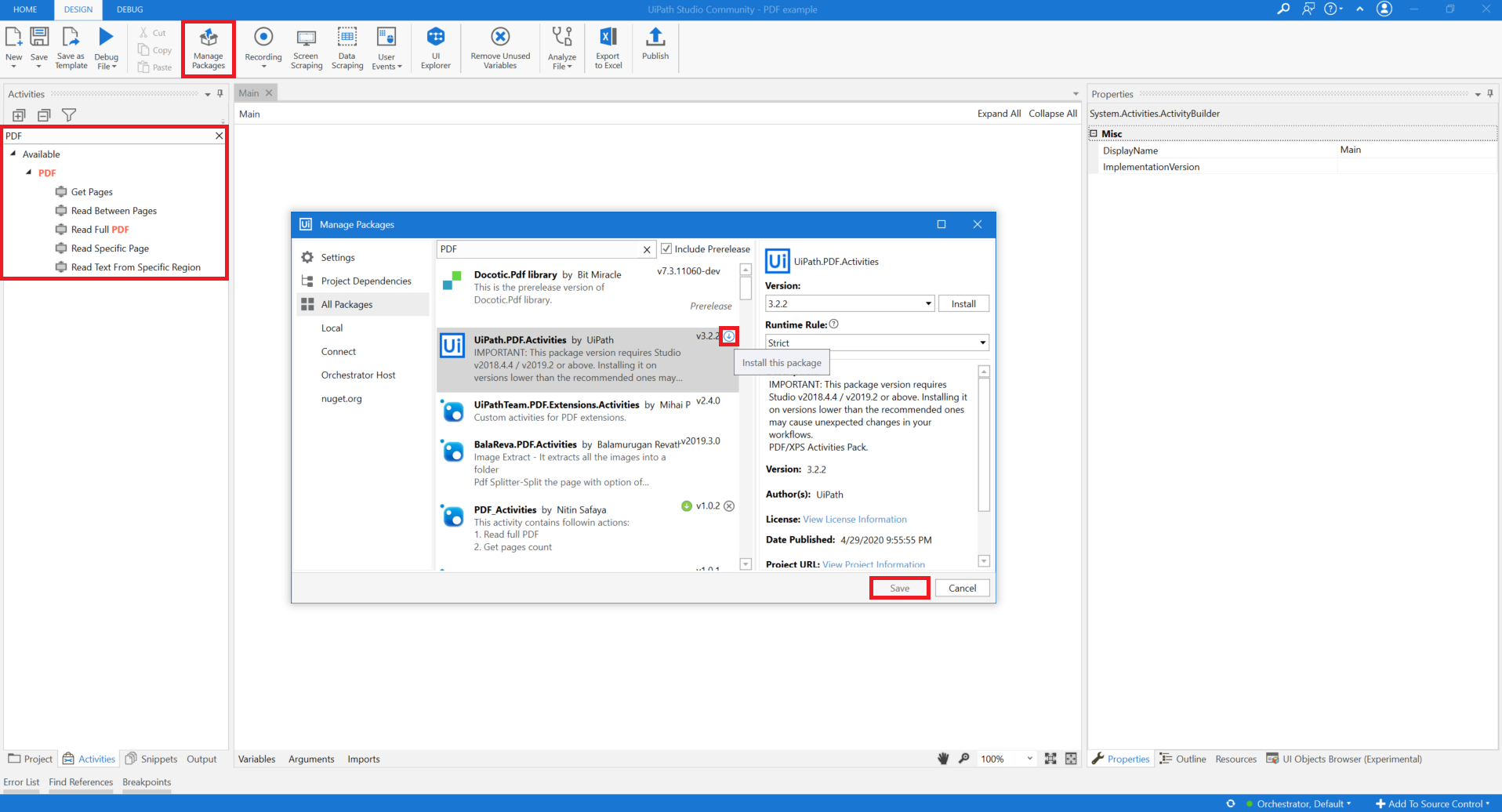
1) 상단 메뉴바에서 Manage Packages를 클릭한다.
2) All Packages를 선택하고 PDF로 검색한다.
3) UiPath.PDF.Activities를 선택하고 ↓를 클릭한 뒤 Save 버튼이 활성화되면 클릭한다.

이제 PDF 액티비티 패키지도 설치했으니 본격적으로 PDF 파일에서 데이터를 추출해보겠습니다.
저는 Native-text format과 Scanned image의 예시를 함께 보여드리기 위해서 이미지와 텍스트가 함께 있는 PDF 파일을 준비해봤는데요. 아래 화면을 보시면 "HM REvenue & Customs" 부분은 Scanned image 부분이고, "Guide to Importing & Exporting Breaking down the Barriers Version38- June 2013 1"까지는 모두 파란색으로 블록설정된 Native-text 부분이라는 것을 확인하실 수 있을겁니다.

1) Read PDF Text 액티비티를 불러온다.
2) Read PDF Text 액티비티에 불러올 PDF 파일 경로를 설정해주고 결과값에 text라는 변수명을 부여한다.
3) Read PDF With OCR 액티비티를 불러온다.
4) Activities Panel에서 OCR을 검색하고 Engine에서 하나를 선택한다.
5) Read PDF With OCR 액티비티의 Drop OCR Engine Acitivity Here에 OCR Engine을 넣어준다.
6) Read PDF With OCR 액티비티에 불러올 PDF 파일 경로를 설정해주고 결과값에 image라는 변수명을 부여한다.
※ OCR(Optical Character Reader) Engine
OCR Engine에는 여러 종류가 있는데 보통은 Google Cloud Vision OCR과 Microsoft OCR이 많이 사용된다고 합니다. 저는 Microsoft OCR을 사용해봤습니다.
여기까지 실행하셨다면 Output Panel에는 어떤 결과값이 있을까요? 아래 화면 빨간칸을 함께 보시겠습니다. Read PDF Text 액티비티의 결과값 text는 말그대로 순수 텍스트, Native-text만 추출해주고, Read PDF With OCR 액티비티의 결과값 image는 이미지까지도 읽어서 기존의 text에 플러스로 이미지 부분이었던 "HM REvenue & Customs" 부분까지 출력해줬습니다.
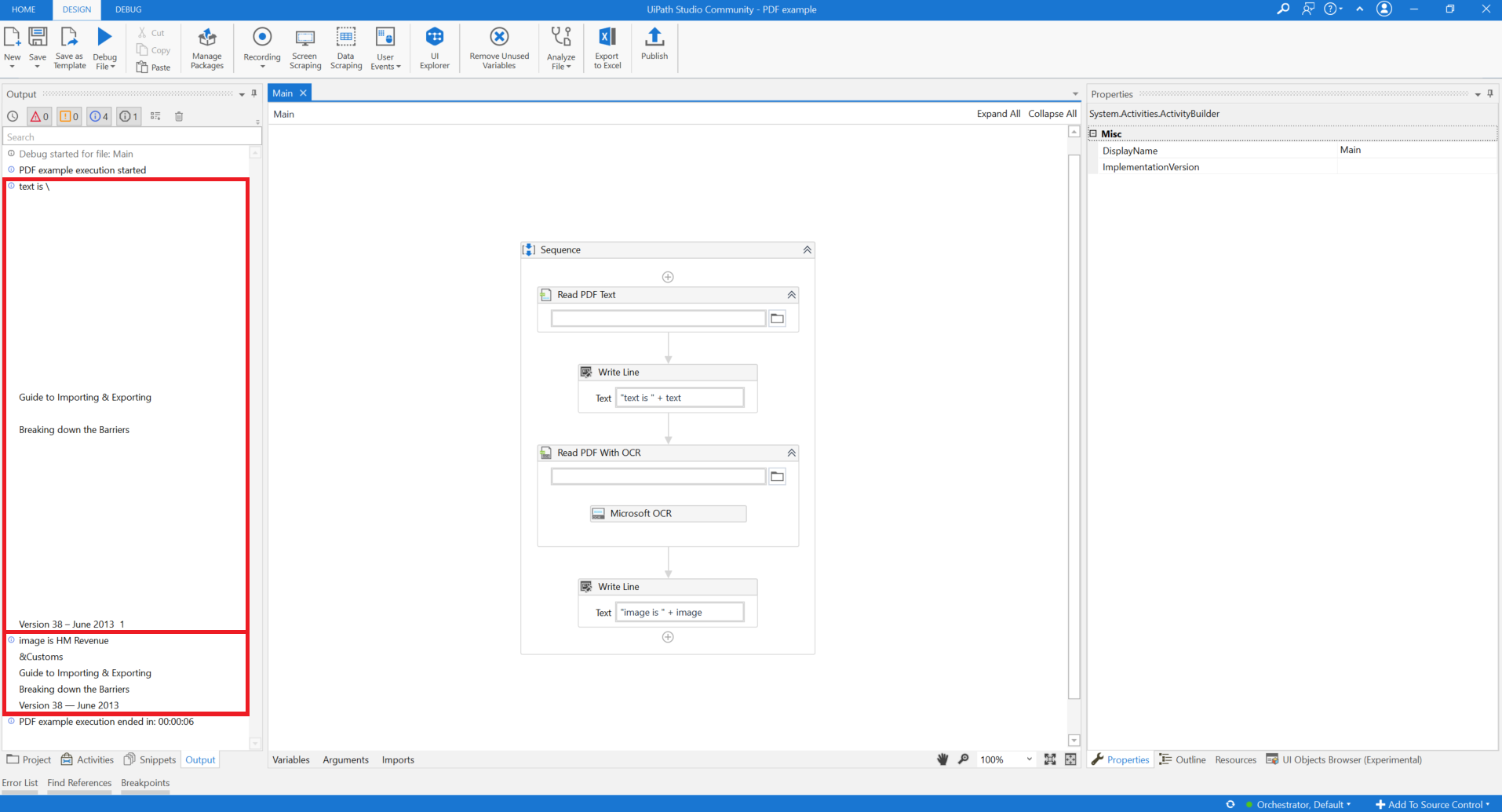
여기까지 보시면 PDF 파일에서 텍스트 뿐만 아니라 이미지까지 읽어올 수 있다는 사실에 심장이 쿵쾅쿵쾅하실텐데요. 사실 제가 예제로 선택한 PDF 파일은 화잘이 굉장히 좋기 때문에 이런 완벽에 가까운 결과값을 얻을 수 있었답니다. 만약에 Scanned image 형식의 PDF 파일이 흐리고 해상도도 낮고 막 잉크가 번져있었다면 엉뚱꺵뚱한 글자들이 출력되었을거에요.
그래도 우리가 Native-text PDF 파일을 다룰 일이 있다면 얼마든지 데이터 추출이 가능하니까요, 필요할 때 유용하게 사용하셨으면 좋겠습니다. 이것으로 오늘의 포스팅을 마치겠습니다.







