크롤링(Crawling)이란 무수히 많은 컴퓨터에 분산 저장되어 있는 문서를 수집하여 검색 대상의 색인으로 포함시키는 기술입니다. 쉽게 말해서 데이터를 수집하는 기술이라고 할 수 있습니다. 인터넷 포털사이트에서 특정 검색어로 검색하고 그 결과 값으로 뉴스 기사 제목, URL, 날짜를 수집해서 엑셀 파일로 저장하는 프로세스를 다뤄보겠습니다.
Uipath 크롤링하는 방법
1) Uipath Studio에서 새로운 프로세스를 생성합니다.
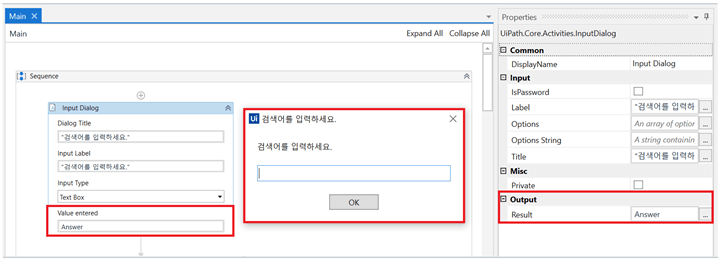
2) Input Dialog 액티비티를 불러와서 사용자가 검색어를 입력할 수 있도록 합니다.
Dialog Title과 Input Label은 팝업창 제목과 내용이기 때문에 자유롭게 입력해주시면 됩니다. 중요한 부분은 사용자가 팝업창에 입력한 답변인 Value entered 부분입니다. 저는 Answer라는 이름의 변수를 만들어서 넣어줬습니다. 사용자가 팝업창에 "환율"이라고 입력한다면 Answer = 환율이 됩니다.
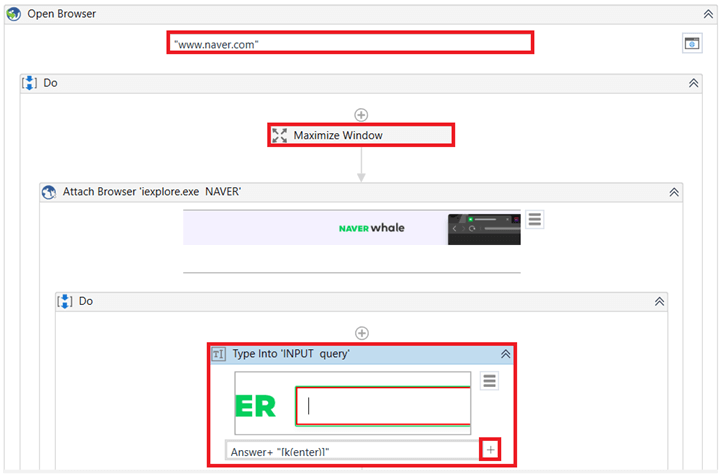
3) Open Browser 액티비티를 불러와서 인터넷 포털사이트 주소를 입력합니다.
인터넷 포털사이트 주소는 문자열이니까 큰따옴표 "" 안에 넣어야 합니다. 인터넷 창을 최대화하고 싶으시다면 Maximize Window 액티비티를 추가할 수 있습니다.
4) Type Into 액티비티를 불러와서 인터넷 포털사이트 검색창에 2)에서 입력된 검색어를 입력합니다.
Type Into 액티비티 안에 있는 "Indicate element inside brower"를 클릭한 후 인터넷 포털사이트 검색창을 선택합니다. 여기에 2)에서 사용자에게 얻은 답변이자 오늘의 검색어가 되는 변수 Answer를 넣어줍니다. 그리고 + 버튼을 클릭해서 Enter를 선택합니다.
5) Click 액티비티를 불러와서 "뉴스"를 선택해줍니다.
4)까지의 프로세스가 검색어를 입력한 후 검색하는 과정이므로 검색 결과가 나왔을 때 뉴스 기사를 크롤링하기 위해 뉴스 탭을 클릭합니다.
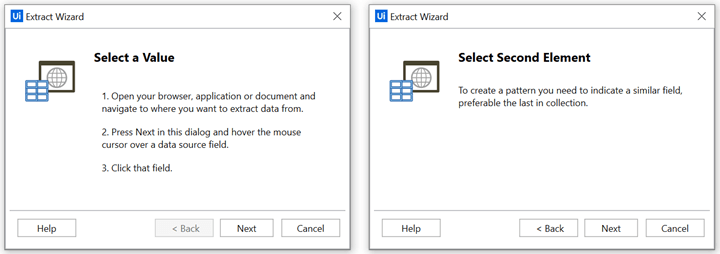
6) Uipath Studio에서 Data Scraping을 클릭하고 크롤링할 뉴스 기사 제목을 선택합니다.
Uipath Studio에서 Data Scraping을 클릭하면 아래 왼쪽 화면처럼 Extract Wizard라는 창이 뜨면서 Select a Value, 즉 크롤링할 기사를 선택하라고 합니다. 인터넷 포털사이트로 가서 뉴스 기사 목록의 제일 위에 있는 첫 번째 기사의 제목을 클릭합니다. 그리고 Next를 클릭하면 아래 오른쪽 화면처럼 Select Second Element, 두 번째 요소를 선택하라고 합니다. 뉴스 기사 목록의 두 번째 기사의 제목을 클릭해주시면 됩니다. 다시 한번 Next를 클릭합니다.
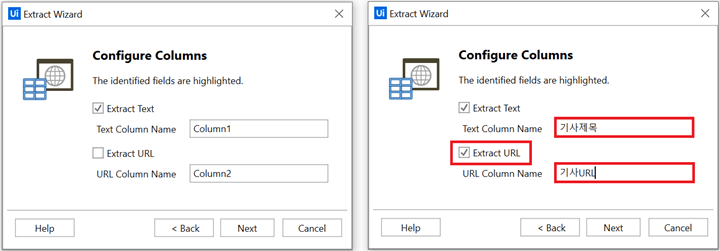
7) 크롤링할 정보와 그 정보를 담을 열(Columns)과 열의 이름(Column Name)을 지정합니다.
Configure Columns는 어떤 정보를 어떤 이름의 열에 표시해줄지 설정하는 부분입니다. 기사 제목만 추출하려면 아래 왼쪽 화면 첫 번째 Extract Text의 체크박스에만 체크하고 기사 URL까지 추출하려면 두 번째 Extract URL 체크박스까지 체크합니다. 그리고 아래 오른쪽 화면에서 해당 정보를 표시할 열 제목을 정합니다. 저는 각각 기사 제목, 기사 URL이라고 열 이름을 설정했습니다.
8) 추가적인 정보를 크롤링하고 싶다면, Extract Correlatd Data를 클릭하고 선택해줍니다.
여기까지 진행하셨다면 Extract Wizard 창에서 Preview Data라고 크롤링된 데이터를 보여줍니다. Maximum number of results라는 부분이 있는데 이 부분을 0으로 설정하면 제한 없이 모든 데이터를 크롤링하고, 특정 숫자 예를 들면 100을 설정하면 100개의 데이터만 크롤링합니다. 기사 제목, 기사 URL 이외의 추가적인 정보까지 크롤링하고 싶으시다면 Extract Correlated Data를 클릭하고 인터넷 포털사이트에서 해당 데이터를 추출하시면 됩니다.
9) Finish를 클릭합니다.
10) 크롤링할 페이지가 여러 페이지인 경우, "Indicate Next Link"라는 팝업창에서 "Is data spanning multiple pages?"라는 질문에 Yes를 선택해줍니다.
인터넷 페이지가 여러 페이지인 경우에는 Is data spanning multiple pages?라는 질문에 Yes를 선택하고 다음 페이지로 넘어가는 화살표나 Next page 버튼을 선택합니다. RPA가 자동으로 다음 페이지로 넘어가서 데이터를 추출해오게 됩니다.

Uipath 크롤링한 데이터 엑셀로 저장
Uipath Studio에서 Data Scraping 액티비티 안에 있는 Extract Structured Data 부분을 보시면 크롤링된 결과값이 DataTable 형식의 ExtractedDataTable이라는 변수명으로 저장되었음을 확인하실 수 있습니다. 이제 이 데이터를 엑셀 파일로 저장해볼까요?
1) Excel Application Scope 액티비티를 불러와서 크롤링 값을 저장할 엑셀파일 경로를 지정해줍니다.
2) Write Range 액티비티를 불러와서 데이터를 입력할 시트(Sheet) 이름과 데이터 입력을 시작할 셀(cell)을 설정하고 입력할 데이터(Input)에 ExtractDataTable을 입력합니다.
Write Range 액티비티는 기본적으로 "Sheet1"과 "A1"이 기본값으로 설정되어 있습니다. Sheet1이라는 이름의 시트의 A1 셀부터 데이터를 입력하겠다는 뜻입니다. 변경 없이 그대로 진행하고 입력할 데이터 Input 값은 앞에서 크롤링으로 추출한 DataTable 형식의 ExtractDataTable을 입력합니다.
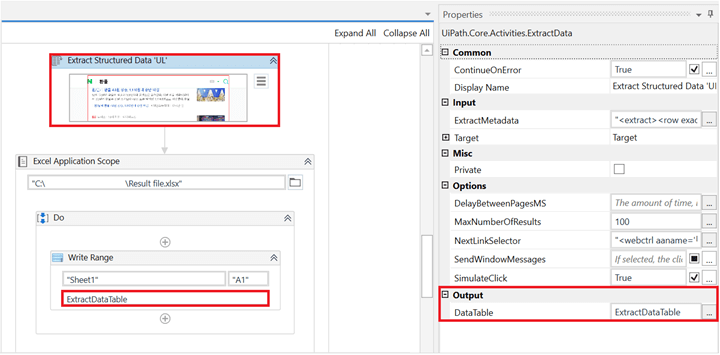
이제 프로세스가 완성되었습니다. 여기까지 진행하신 후에 프로세스를 실행하면 자동으로 대화상자 팝업창이 뜹니다. 검색어를 입력하면 인터넷 포털사이트 창이 열리면서 최대화되고 해당 검색어로 뉴스를 한 페이지씩 넘기면서 기사를 크롤링합니다. 마지막으로 사전에 지정했던 경로의 엑셀 파일을 열어보시면 크롤링된 데이터 결과값을 확인하실 수 있습니다.







